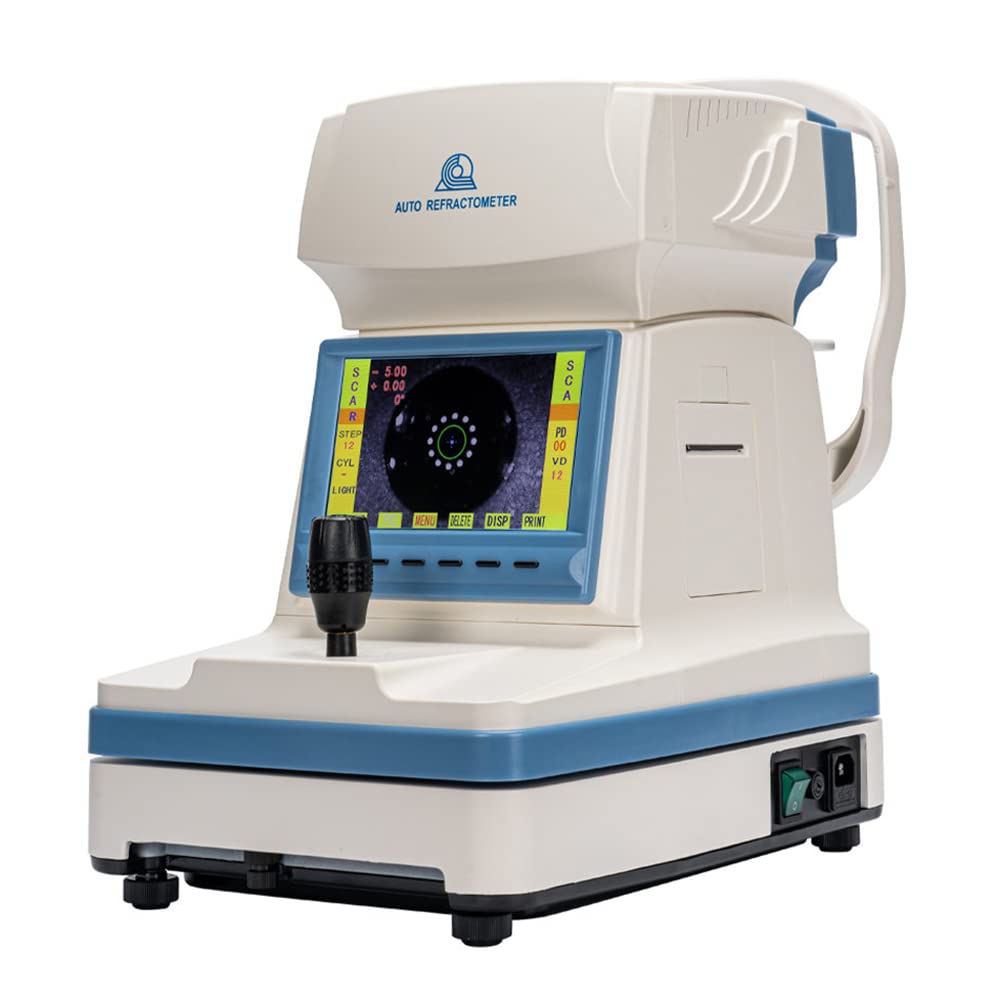
It’s a good machine for the price. It works as promised. The manual (very roughly translated from Chinese to English) that comes with it isn’t very clear. Here are better instructions (my thanks to Claude.ai).

It’s a good machine for the price. It works as promised. The manual (very roughly translated from Chinese to English) that comes with it isn’t very clear. Here are better instructions (my thanks to Claude.ai).

For they stress hardware without limit
For they know flow to the point of triviality
For they wage war against latency
For they invest in technology
and test it mercilessly
For they exemplify the Simulation Argument
and create worlds
Posting here because I couldn’t find any instructions online, and I figured it out. I use the CF-33 because it’s one of very, very few laptops with a daylight-visible display.
I opened up mine (a Mk1) was because my touchscreen went crazy – the mouse position jumped around, and the mouse clicked at random when it’s not supposed to. Disabling it in Windows only worked until the next boot – it re-enables itself (not supposed to, but it does).
[Note: I haven’t tried it, but I’ve read that disabling the touchscreen in “Panasonic PC Hub” works on some Toughbooks (I don’t know if it works on the CF-33). You might want to try that first if that’s your problem.]
So I wanted to disconnect the touchscreen by unplugging the internal cable – the machine also has a touchpad and I normally use a Bluetooth mouse anyway. Here’s how I did it, and how you can open up yours.
General tips:
1 – Don’t force anything.
2 – You can run the machine without batteries in it, and without the dock/keyboard – just plug in the AC cable. If you want to work it once the touchscreen is disconnected or without the dock, I suggest a USB mouse and/or keyboard (if you want both you’ll need a USB hub – without the dock there’s only one USB socket).
3 – I highly recommend using a set of JIS screwdrivers (not Philips). The screws look like Philips but they’re JIS which are slightly different and if you use a Philips screwdriver you can easily strip the heads. This is the best set I found at a reasonable price: https://www.amazon.com/VESSEL-precision-screwdriver-set-TD-56/dp/B000CED236 They’re Japanese made and incredibly good quality – $14.
4 – Try to avoid pressing the power button when fiddling with it while it’s running. Esp. if it starts a Windows Update and says “don’t turn off your computer”. I managed to press it, but it restarted the update on the next boot so I guess it’s not critical all the time. Or I was lucky.
5 – The CF-33 won’t display anything if the battery door is open. If it seems like it should be running and the battery door is open (or removed), that’s what’s going on.
6 – Put screws back in the holes they came from after removing parts. This will help you remember where they go.
Open the battery door, take out the batteries. It’ll look like this:

Inside the battery compartment (per that photo), there’s a small metal tab (looks like aluminum to me) held by one screw on the right, just 3/4 of an inch north of the right battery. That’s how the machine senses if the battery door is open. If that metal tab isn’t next to the sensor underneath (when the door is closed), the machine will run but the display will not operate. (The black plastic spring loaded plunger in the middle that looks like it has a switch to detect if the door is open has nothing to do with it. That is just there to push up the battery door once you unlatch it. It has no electronics.)
Remove the 3 sliver screws on the silver plate that covers the other side of the CF-33 and stick out into the battery compartment. Then you can take off the plate that covers the other side (not covered by the battery cover) of the CF-33. This is the silver outside plate that surrounds the back camera and says Panasonic and TOUGHBOOK on it.
At this point you’ll see a door that can be removed by taking out a bunch of screws. The door contains the rear camera. I don’t know if you need to remove it or not (I did). The purpose of the door seems to be to allow upgrades – under the door are two radios (cellular and Bluetooth/Wifi) and I think this is where the fingerprint reader goes (I don’t have one).
Once you get the door off, disconnect the rear camera cable by flipping up the black latch at the end of the cable by 90 degrees (these open at the end where the cable goes), to make it stand up from the PCB. Slide out the cable, put the black latch back down.
Next to the fan you’ll see a silver door with 3 screws – that holds the SSD. No need to mess with that (the SSD will be exposed in the next steps anyway).
Now remove the 4 silver bumper button things on the corners opposite the docking connector. (Two on each side of the machine.) You need a hex driver – I think it’s 2mm but I used a 3/32 inch and it mostly worked ok.
Next remove all the screws around the edges of the machine holding in the black plastic/rubber edges. Then remove the rubber edges – first from the short sides of the machine, then from the long sides (the order matters). Then remove all the screws around the perimeter of the machine. You also need to remove the two screws left and right of the fan (in deeper holes).
Once you get all those out, the cover should be loose around all the edges but stuck in the middle. It’s held by the SIM card socket. Take out the one screw holding the SIM card socket PCB and slide it out. Then you can take off the cover. (It’s possible if you don’t have a SIM card in there this isn’t necessary.)
Here’s what it looks like once you get the cover off:

The touch screen cable is the little white one (about 5 or 6 contacts) that is perpendicular to the SSD. On the opposite side of the SSD from the fan. In the photo it says SUMITOMO on it.
Lift up the plastic protecting it (in the area with the blue marker in the photo) and flip up the black latch at the end of the cable by 90 degrees, to make it stand up from the PCB. Slide out the cable, put the black latch back down. If it takes much force you’re doing it wrong.
That disconnected the touch screen.
Now reassemble the whole thing in the opposite order.
Getting the mainboard cover on is tricky because (again) the SIM card socket is in the way. Don’t try to remove the plastic bracket – you don’t need to and it resists. Instead, remove the SIM card (if you have one in there), remove the one screw holding the PCB and put the cover on. Then slide the SIM PCB into place and replace the screw. Then put the SIM back in and close the little door.
There are 5 screws that are longer than the others. Two of these go thru the black plastic shell that holds the pen, then thru the smaller cover, then into the main machine. 2 more go on either side of the docking connector. I don’t know where the last one goes.
Once you get it all together everything works except the touch screen (which got disconnected). But the touchpad still works (as does any mouse you connect).
I hope this helps someone.
According to The Economist, disinformation campaigns (often state-sponsored) use “AI to rewrite real news stories”:
In early March [2024] a network of websites, dubbed CopyCop, began publishing stories in English and French on a range of contentious issues. They accused Israel of war crimes, amplified divisive political debates in America over slavery reparations and immigration and spread nonsensical stories about Polish mercenaries in Ukraine… the stories had been taken from legitimate news outlets and modified using large language models.
Deep fakes of still images and now video clips are similarly based on legitimate original photos and video. Detecting such fakery can be challenging.
Disinformation comes from publishers (social media posters, newspapers, bloggers, commenters, journalists, photographers, etc.) who invent or misquote factual claims or evidence. Ultimately, we trust publishers based on their reputation – for most of us an article published by chicagotribune.com is given more credence than one published by infowars.com.
An obvious partial solution (that I haven’t seen discussed) is for publishers to digitally sign their output, identifying themselves as the party whose reputation backs the claims, and perhaps including a permanent URL where the original version could be accessed for verification.
Publishers who wish to remain anonymous could sign with a nym (pseudonym; a unique identifier under control of an author – for example an email address or unique domain name not publicly connected with an individual); this would enable anonymous sources and casual social media posters to maintain reputations.
Web browsers (or extensions) could automatically confirm or flag fakery of the claimed publisher identity, and automatically sign social media posts, comments, and blog posts. All that’s needed is a consensus standard on how to encode such digital signatures – the sort of thing that W3C and similar organizations produce routinely.
Third party rating services could assign trust scores to publishers. Again, a simple consensus standard could allow a web browser to automatically retrieve ratings from such services. (People with differing views will likely trust different rating services). Rating services will want to keep in mind that individual posters may sometimes build a reputation only to later “spend” it on a grand deception; commercial publishers whose income depends on their reputation may be more trustworthy.
Posts missing such signatures, or signed by publishers with poor trust scores, could be automatically flagged as unreliable or propaganda.
Signatures could be conveyed in a custom HTML wrapper that needn’t be visible to readers with web browsers unable to parse them – there’s no need to sprinkle “BEGIN PGP SIGNED MESSAGE” at the start of every article; these can be invisible to users.
Signatures can be layered – a photo could be signed by the camera capturing the original (manufacturer, serial number), the photographer (name, nym, unique email address), and publisher, all at the same time, similarly for text news articles.
When a new article is created by mixing/editing previously published material from multiple sources, the new article’s publisher could sign it (taking responsibility for the content as a whole) while wrapping all the pre-existing signatures. A browser could, if a user wanted and the sources remain available, generate a revision history showing the original sources and editorial changes (rewording, mixing, cropping, etc.). Trust scores could be automatically generated by AI review of changes from the sources.
Video could be signed on a per-frame basis as well as a whole-clip or partial-clip basis. Per frame signatures could include consecutive frame numbers (or timestamps), enabling trivial detection of selective editing to produce out-of-context false impressions.
If there’s a desire for immutability or verifiable timestamps, articles (or signed article hashes) could be stored on a public blockchain.
Somebody…please pursue this?
From hard-won experience. Applies to banks, cable companies, airlines, etc. Virtually all large organizations that deal with the general public (vs. other businesses) have incompetent staff – the general public won’t pay what it costs for better (maybe someday AI can do better; let us hope).
0. Be polite, no matter how justified to be otherwise. They can’t help their own incompetence. It’s not their fault they’ve wasted 4 hours of your time and $1000 of your money.
A drop of honey goes a long, long way. Say “thank you” often.
Be the nicest person they’ve spoken to today.
1. Get their name. WRITE IT DOWN.
Ask them to spell it if necessary.
Use it once in a while (this is both part of being polite, and reminds them that you can complain about them if they don’t treat you right).
2. Ask “How can I reach you if we get disconnected? (That happens to me a lot.)”
Write down whatever they say – their name, employee id, extension, case #, whatever.
If you miss something ASK THEM TO SPELL IT.
WRITE IT DOWN.
This goes along with getting names – if you get disconnected and have to start over with someone else, or if the org doesn’t deliver what was promised and you need to call back later, they are much more likely to believe you if you can refer to a person/phone extension/employee id etc. that identifies who you dealt with.
Since you can back up your claim with a contact person, they will assume that what you claim was said earlier is true (remember, most orgs are incompetent, not dishonest).
3. Whatever they promise, GET IT IN WRITING.
If you have proof they said it, the organization is committed to it – if the person promised something they were not supposed to, that’s their problem, not yours – they represent their organization. Hold them to it.
If they can’t do something immediately, ask for an email note promising to do it in the future.
4. If the person is excessively incompetent and just can’t understand, or doesn’t have the authority to fix the problem (happens a lot!), or just can’t figure out how, ASK TO SPEAK TO THEIR MANAGER. Politely.
DON’T go over what the previous person said or got wrong – just start over with the manager.
Go to step 0. (You may end up having to talk to multiple levels of managers before you get to someone who can understand and fix the problem. Just keep going up. Unless you’re talking to the president of the company, whoever you’re talking to has a manager.)
5. VERIFY EVERYTHING. Prices, names, dates, services, etc.
Before you get off the phone. Read it all back to them to confirm.
When you tell them things, make them read it back to you, to confirm they got it right.
Extra credit: Learn and use the ICAO phonetic alphabet:
Alfa November Bravo Oscar Charlie Papa Delta Quebec Echo Romeo Foxtrot Sierra Golf Tango Hotel Uniform India Victor Juliet Whiskey Kilo Xray Lima Yankee
Mike Zulu
So “BCDE123” is just “bravo charlie delta echo one two three”. Don’t waste time saying “B for bravo”.
I just read John von Neumann’s First Draft of a Report on the EDVAC, a tremendously influential 1946 document about computer architecture. A paper copy is available on Amazon, and the identical document as a PDF here.
Written after his experience with ENIAC (where he, famously, configured the plugboards to implement stored instructions in memory), the document describes the architecture of a (then) next-generation machine. Supposedly this early draft (the only draft he ever produced) was circulated widely and led to many implementations of similar machines in the late 1940s.
It’s a fascinating historical document. One thing that jumped out at me (no pun intended) is that nowhere in the document does he mention the idea of conditional branches – without those it’s extremely difficult or impossible to make the machine Turing-complete.
Also, he seems to have conceived the machine purely as a programmable calculator. The concept of what we’d call “data processing” is completely absent.
Von Neumann is considered one of the smartest people to have ever lived – Hans Bethe said “I have sometimes wondered whether a brain like von Neumann’s does not indicate a species superior to that of man”, and Edward Teller (a very competitive guy) admitted that he “never could keep up with John von Neumann.”
Teller also said “von Neumann would carry on a conversation with my 3-year-old son, and the two of them would talk as equals, and I sometimes wondered if he used the same principle when he talked to the rest of us.”
I think this just goes to show how difficult it is to predict even the future of a narrow technology.
Here’s a Python script that makes Windows open a URL (in your default browser) when you execute (double click) a Linux .desktop file that contains a URL.
If you use both Windows and Linux, and save links to websites from a browser in Linux, the link will become a .desktop file, which can be opened by Linux. .desktop files are a lot like Windows “shortcut” files, but are (of course!) incompatible with them.
This script lets Windows open the website link saved in a .desktop file.
It relies on Python already being installed in your Windows system.
You can use it at the Windows command line like this:
python launch.desktop.py <.desktop file>
To use it at the Windows GUI (to be able to double-click on a .desktop file to launch it), put the following line in a batch file in your executable path somewhere (one place that would work would be C:\WINDOWS\System32) as “launch.desktop.bat”:
python "%~dp0launch.desktop.py" %1
Then put the Python script in the same folder where you put the batch file, as “launch.desktop.py”:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Launches a Linux .desktop file that contains a URL, on Windows.
Tested on Win10, Python 3.11.
Note: Doing this in a Windows batch file is a problem because findstr doesn't want to open files with special characters in them
(which Linux likes to put there). There are ways around that (make temp files), but Python doesn't mind the characters.
"""
__author__ = 'NerdFever.com'
__copyright__ = 'Copyright 2023 NerdFever.com'
__version__ = ''
__email__ = 'dave@nerdfever.com'
__status__ = 'Development'
__license__ = """'Copyright 2023 NerdFever.com
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License."""
import os, sys, subprocess
def main():
if len(sys.argv) != 2:
print(os.path.basename(__file__))
print("Launches a Linux .desktop file that contains a URL, on Windows.")
print("Usage: python", os.path.basename(__file__), "<filepath>")
return
filepath = sys.argv[1]
if not os.path.exists(filepath):
print(f"Error: {filepath} does not exist!")
return
# open file, scan for "URL=" or "URL[anything]=", get URL from remainder of line
url = None
with open(filepath, "r") as f:
for line in f:
if line.startswith("URL="):
url = line[4:].strip()
break
elif line.startswith("URL["):
url = line[line.find("]")+1:].strip()
break
if url is None:
print(f"Error: {filepath} does not contain a URL!")
return
# run "start" on the URL (launch default browser configured in Windows)
subprocess.run(["start", url], shell=True)
if __name__ == "__main__":
main()
The first time you double-click on a .desktop file, Windows will say it doesn’t know how to open it, and offer to let you choose a program on your PC for that. Choose “launch.desktop.bat” and check the box “Always use this app to open .desktop files”. Done.
This brief post is here solely as prior art to make it more difficult for someone to patent these ideas. Probably I’m too late (the idea is so obvious the patent office probably has a dozen applications already), but I’m trying.
GOALS
One of my pet projects for years has been finding a way to promote civil discussion online. As everyone knows, most online discussion takes place in virtual cesspits – Facebook, Twitter, the comments sections of most news articles, etc. Social media and the ideological bubbles it promotes have been blamed for political polarization and ennui of young people around the world. I won’t elaborate on this – others have done that better than I can.
The problem goes back at least to the days of Usenet – even then I was interested in crowdsourced voting systems where “good” posts would get upvoted and “bad” ones downvoted in various ways, together with collaborative filtering on a per-reader basis to show readers the posts they’ll value most. I suppose many versions of this must have been tried by now; certainly sites like Stack Exchange and Reddit have made real efforts. The problem persists, so these solutions are at best incomplete. And of course some sites have excellent quality comments (I’m thinking of https://astralcodexten.substack.com/ and https://www.overcomingbias.com/), but these either have extremely narrow audiences or the hosts spend vast effort on manual moderation.
My goal (you may not share it) is to enable online discussion that’s civil and rational. Discussion that consists of facts and reasoned arguments, not epithets and insults. Discussion that respects the Principle of Charity. Discussion where people try to seek truth and attempt to persuade rather than bludgeon those who disagree. Discussion where facts matter. I think such discussions are more fun for the participants (they are for me), more informative to readers, and lead to enlightenment and discovery.
SHORT VERSION
Here’s the short version: When a commenter (let’s say on a news article, editorial, or blog post) drafts a post, the post content is reviewed by an AI (a LLM such as a GPT, as are currently all the rage) for conformity with “community values”. These values are set by the host of the discussion – the publication, website, etc. The host describes the values to the AI, in plain English, in a prompt to the AI. My model is that the “community values” reflect the kind of conversations the host wants to see on their platform – polite, respectful, rational, fact-driven, etc. Or not, as the case may be. My model doesn’t involve “values” that shut down rational discussion or genuine disagreement (“poster must claim Earth is flat”, “poster must support Republican values”…), altho I suppose some people may want to try that.
The commenter drafts a post in the currently-usual way, and clicks the “post” button. At that point the AI reviews the text of the comment (possibly along with the conversation so far, for context) and decides whether the comment meets the community values for the site. If so, the comment is posted.
If not, the AI explains to the poster what was wrong with the comment – it was insulting, it was illogical, it was…whatever. And perhaps offers a restatement or alternative wording. The poster may then modify their comment and try again. Perhaps they can also argue with the AI to try to convince it to change its opinion.
IMPORTANT ELABORATIONS
The above is the shortest and simplest version of the concept.
One reasonable objection is that this is, effectively, a censorship mechanism. As described, it is, but limited a single host site. I don’t have a problem with that, since the Internet is full of discussions and people are free to leave sites they find too constraining.
Still, there are many ways to modify the system to remove or loosen the censorship aspect, and perhaps those will work better. Below are a couple I’ve thought of.
OVERRIDE SYSTEMS
If the AI says a post doesn’t meet local standard, the poster can override the AI and post the comment anyway.
Such overrides would be allowed only if the poster has sufficient “override points”, which are consumed each time a poster overrides the AI (perhaps a fixed number per post, or perhaps variable based on the how far out of spec the AI deems to the post); once they’re out of points they can’t override anymore.
Override points might be acquired:
Re buying them with money, a poster could effectively bet the AI about the outcome of human moderator review. Comments posted this way go online and also to a human moderator, who independently decides if the AI was right. If so, the site keeps the money. If the moderator sides with poster, the points (or money) is returned.
The expenditure of override points is also valuable feedback to the site host who drafts the “community values” prompt – the host can see which posts required how many override points (and why, according to the AI), and decide whether to modify the prompt.
READER-SIDE MODERATION
Another idea (credit here to Richard E.) is that all comments are posted, just with different ratings, and readers see whatever they’ve asked to see based on the ratings (and perhaps other criteria).
The AI rates the comment on multiple independent scales – for example, politeness, logic, rationality, fact content, charity, etc., each scale defined in an AI prompt by the host. The host offers a default set of thresholds or preferences for what readers see but readers are free to change those as they see fit.
(Letting readers define their own scales is possible but computationally expensive – each comment would need to be rated by the AI for each reader, rather than just once when posted).
In this model there could also be a points system that allows posters to modify their ratings, if they want to promote something the AI (or readers) would prefer not to see.
Want a real archival backup that your great-great-grandchildren will be able to read?
Most media (CD-Rs, tape, disk, I think also flash) decay after 10 to 20 years. Having lots of redundant copies helps a little, but only a little.
If you want things to last a LONG time (say, 100+ years), I think the best options today are:
1 – M-DISC BluRay discs. They are designed to last 100 years. Of course this hasn’t been tested – the number is based on projections and knowledge of the decay mechanisms. From what I’ve read the chance of them being readable after 200 or 300 years is pretty good, if they’re stored in a dark cool place (say 5 to 10 C). Probably purging the oxygen from the container (flush it out with nitrogen) is a good idea too.
And, of course, multiple redundant copies.
2 – Multiple external HDDs, but keep them running the whole time (bearings often seize up after a few years if they’re not run). Actively migrate the data to new hardware every 10 years or so. (This requires money and effort of course.)
My understanding is that the ZFS (Zettabyte File System) is the way you’d want to store data across multiple HDDs – you can adjust the redundancy level as you like and ZFS will use all available space to create more redundancy if you want (as you originally where thinking).
3 – If you only have a little bit of data to store (< 1 MByte) – punched paper tape or punched cards. Store them in sealed containers purged of oxygen, in a dark cool place. If you’re really serious, use punched cards made of out of solid gold (gold is inert), and put the sealed container in a Nazi submarine and sink it to the bottom of an ocean.
Are you concerned that 100+ years from now nobody will have the hardware to read the media? Don’t be. If civilization doesn’t fall, it won’t be a problem (if it does fall, yes a problem).
I don’t think there’s any storage media used 100 years ago that we can’t today build a new reader for – easily and cheaply. And of course there will always be historians and museums who keep readers functional for common media.
Re uncommon media, a few years ago there was a project to recover data from some 50 year old tapes with data from NASA spacecraft. There were no working tape drives that could read it, so they built a new one from scratch. Anything we can build today at all, the technology of the future (assuming civilization doesn’t collapse) will find easy to duplicate.
I feel like almost every day I see great business opportunities that nobody seems to be pursuing.
Here’s a straightforward one – make a decent cell tower map website. Put a few ads on it. (Non pop-up, non-blocking ads – you don’t want to drive your users away!)
It’s easy – the (United States) data is free from the FCC. And it doesn’t already exist.
The best one out there that I’ve found sucks hard – should be easy to do better.
Build it on top of Google Maps (cheap), OpenStreetMap (free), or Bing Maps (I don’t know).
So far others who have tried to do something similar:
Do better. This seems pretty easy and quick to me.
Don’t go around saying that there are no straightforward ways to start a business and make money. Just look around yourself and solve problems that haven’t been solved yet – they’re everywhere!
The world rewards those who fix it.