UPDATED 2 December 2019:
Since this was written I’ve bought a 2nd Model 3 (for myself; it’s red with dual motors). Below, I’ve added comments [in brackets like this] on things that have changed since June 2018. There have been many software updates and improvements.
ADDED 3 August 2018:
We’ve had the car for a month now. There’s one really nice thing about it that I completely didn’t expect (maybe I should have).
Every morning, you start with a full “tank of gas”.
Because you charge at home, the car is fully charged every morning. That’s enough for 5 or 6 hours of driving – far more than we ever do in a single day (except for one or two road trips each year – there are Superchargers for that, but we haven’t used one yet, so I’ll ignore that here).
This means that, effectively, you never need to even think about buying gas. The car is “full” every morning, and never runs out during the day.
This is an amazing and unexpected benefit. The time saved seems small at first, but those 15 minute out-of-your way stops add up. And the routine worry “can I get there without buying gas?” simply never comes up.
Once the $35,000 model is on the market, other car companies are going to have a big problem. For most people, buying any other sedan in that price range is just going to feel…stupid.
Yesterday (2018-06-27) we took delivery of my wife’s new Tesla Model 3.
It’s blue, with every possible option at the time – the long range battery, self-driving software (to be delivered), 19″ wheels, etc. But not the performance or dual motor stuff; those weren’t yet announced when Tesla was ready to deliver it.

Not our car – but looks just like it
We waited two years to get it – she placed a deposit for it a couple hours before the unveiling, less than 10 minutes after Tesla opened the website for orders.
So far she’s driven it for about 2 miles, and me for about 80.
My initial impression is absolute delight – it’s a fantastic car. It’s comfortable. It looks great inside and out. It handles wonderfully. It’s far quicker than anything I’ve ever owned (and I’ve owned two turbocharged sedans and two Mazda Miatas – 1990 and 2008 – and this is the standard, non-performance version).
I won’t talk about the unique control layout (plenty of others have written about it) except to say it takes all of 15 seconds to “get used” to driving with it. (Except for remembering how to open the glovebox – you have to click on the screen.)
It is, of course, utterly silent. The only thing you hear is the tires against the road, unless the A/C fan is on (or the audio system, which is truly excellent).
That said, it’s not, of course, perfect.
For one thing, any car as new and revolutionary as this is bound to have some things that just haven’t had time to be fully polished, from a design viewpoint.
And, it was built when Tesla was at peak “production hell” on the Model 3, trying to ramp output past 5000 cars/week. It’s naturally difficult to vastly increase the quantity of production while maintaining quality at the same time, and I fully expected at least minor issues.
So far, with one major exception (the GPS didn’t work – see below; it’s fixed now), I’ve been pleasantly surprised. Based on my car (a sample of one), Tesla has succeeded in prioritizing the things that matter most – the car is solid and well put-together, with absolutely no rattles or loose bits. Everything related to fundamental function – tires, suspension, motors, brakes, steering, handling, doors, windows, wipers, lights – works absolutely perfectly, with zero design or manufacturing issues.
There are issues – but they’re all niggles and minor things (again, except for the broken GPS).
Below, listed by the date I discovered them, is my list of imperfections on the car. I’m listing them here (a) because lots of people seem interested and (b) to let Tesla know about them, so they can fix them in future cars.
So far, none of them make me regret buying the car for a moment – I’d do it again in a flash. (Full disclosure: I’m a Tesla shareholder.)
2018-06-27 (day of delivery)
Design issues
- Trunk lining is quite thin, doesn’t stay in place well. Maybe they tried too hard to save weight. [My newer Model 3 from December 2018 didn’t have this issue.]
Manufacturing issues
- Damaged plastic cosmetic cover on left hood hinge (on inside of hood; not clear why these covers are even needed) [Store removed it; promised eventual replacement] [Newer car didn’t have these parts at all – they were unnecessary in the first place.]
- The GPS on my car doesn’t seem to work. It thinks it’s in northern California all the time (it’s actually in the suburbs of Boston). The car updates it’s position as I drive, I think based on the wheels spinning and turning (could be inertial), but only relative to where it thinks it started from. Tesla delivery people said it’ll “sync up” with the correct location after a few miles of driving, but after 78 miles it hasn’t. (I suspect store folks knew something was wrong but didn’t want to deal with it on delivery day. Maybe I’m being unfair.) UPDATE: This fixed itself about 4 days later. Tesla support called back and told me this was a known software bug, but the car fixes itself once it hasn’t been driven for about 16 hours. [Newer car didn’t have this issue.]
- Battery cover in the frunk is a bit loose on the right side – not enough clips or something. [Newer car didn’t have this issue.]
2018-06-28
Design issues
- Dome light LED PWM rate is too low (noticeable flicker is too low)
- Dome light takes too long to go out after pressing the button (too much dramatic slow fade)
- “Walk Away Lock” should be part of the Driver Profile (instead of global). [It is, now. Fixed issue.]
- Phone charging dock has no adjustment for phone case thickness. My phone doesn’t fit without taking it out of the case. (I expect aftermarket fixes for this, but they shouldn’t be needed) [There are indeed aftermarket solutions, for example https://www.helloskyline.com/collections/all/products/case-friendly-dock-adapter-for-tesla-model-3, which works well.]
- There’s no way for an owner to enable someone else (like me, the husband) to use their phone to start the car, except by emailing Tesla to ask them to do it manually. Should be possible in the owner’s online Tesla account. (Car can be started with the key card, however.) [This is “fixed”, sort of, by me logging into the Telsa app on my phone using my wife’s username/password. Then I can drive her car without a key. It’s not a great solution (sharing passwords!) but it’s good enough.]
- Car defaults to charging to 90% maximum (to extend LiIon battery life). That’s fine (and you can disable it to allow 100% charge), but the car should explain it better – I had to call and ask.
- There’s a strip of rubber-like material around the bottom of the driver’s seat, just below the more normal plastic material above that strip. Feeling the rubbery stuff blind for the first time (while driving), I thought there was grease or something yucky there left from manufacturing. Poor choice of material. [Didn’t notice this problem on the newer car.]
- A printed Owner’s Manual should really be included with the car (it’s online as a PDF)
- No way to search the built-in Owner’s Manual, or even to scroll thru the whole thing in sequence without going back to the menu for each tiny section. (It’s pretty useless, which is why I had to download the PDF. OTOH, I seem to be the only person on the planet who actually reads Owner’s Manuals. I do skip the warnings, at least.)
Manufacturing issues
- “T” logo illumination on charging port isn’t even (rightmost 5% of logo remains dark) [Newer car didn’t have this issue.]
- “T” logo on hood is not quite centered (either that or the license plate holder isn’t). [Newer car didn’t have this issue.]
- Weird (very minor) imperfection in display screen – it’s not dirt. Here’s a photo: [Newer car didn’t have this issue.]
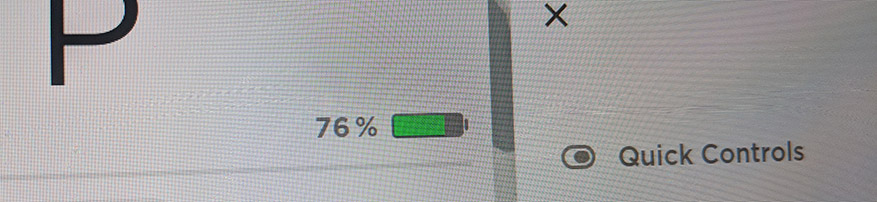
Ignore the beat patterns and color fringing – those are camera artifacts. It’s the smudges in the middle I’m talking about.
Bonus
Here’s a video of a spider crawling around on the rear view camera:
2019-06-30
Software issues
- The charging cable is normally latched in, and is released by a solenoid when you press a button on the cable end. Except when the car is locked – then the release button is disabled. But the release button doesn’t work if the car has been charging for a “long” time – even if the car isn’t locked. The only way I’ve found to re-enable the release button is to open a car door – this seems to wake something up. I haven’t figured out exactly how long “long” is – it’s something > than 30 minutes, and <= reaching full charge. Pretty clearly a software bug.
2019-07-07
More than a week later. Haven’t found a single new thing to add to this list. I’m impressed.
2019-08-11
The car has 1700 miles on it now, and it’s first scratch (my fault when parking – it’s really minor).
Somehow the more I drive it, the more I like it. The car is just “stupid good”. It feels like a magic, silent, carpet. (If that makes any sense.)
A few more imperfections – all software issues (some of these are from my wife – it’s her car):
Software issues – from the wife
- She feels very strongly that the car should never lock itself when in our own garage. (Even if she’s not carrying her phone.) I don’t feel so strongly, but it seems this would be easy to do in software (don’t lock based on GPS or WiFi SSID). [This is fixed now – the auto-lock is a per-driver setting now, not a per-car setting.]
- The “car rolls backward on steep hills” (without the brake on). I think she’s used to automatic transmissions that try to “creep” forward whenever the brake isn’t on – except for very steep hills, this prevents the car from rolling back, and that if the Telsa was in “creep” mode (there is one), it’d act the same. Still, given how smart the car is, it seems silly that it rolls backward when in Drive – the car should just automatically prevent that with the brakes, unless in Reverse or Neutral. [Fixed now – there’s a setting that automatically applies the brakes whenever the car comes to a stop. The brakes release instantly when you press the accelerator. Very nice solution.]
- She’d like an option to make the font much bigger on the screen. She can’t read anything without reading glasses (but she can drive without them).
- It was hard to figure out how to turn off “Christmas mode” (an Easter Egg).
Software issues – from me
- Car doesn’t warn when there’s traffic in your blind spot (when changing lanes). My other car has “BLIS” (Blind Spot Information System) that blinks the side mirror (and beeps) when your turn signal is on but there’s traffic in that direction. [Partly fixed – the car beeps and shows a warning on the main screen. There’s still no warning light on the side mirror, which would be better.]
- The voice recognition doesn’t seem to understand anything I ask it. Things like “Directions to Home”, “Navigate to Home”, “Navigate to <address>”, “Open the glovebox”, etc. Each time it transcribes what I said correctly, then says it doesn’t understand and “Try again”. (I haven’t found anything useful that it does understand.) To be fair – I’m used to Google Assistant (a high bar), which handles all of this fine. (Given that Tesla uses Google Maps, I don’t see why they can’t partner with Google to do voice recognition, too.) [Still a problem as of late 2019. Why it can’t just hand off queries to Google Assistant, I have no idea. My phone is vastly better at these things.]
- Autopilot doesn’t drive smoothly. It’s too aggressive about maintaining distance from the car in front – unless a collision is imminent, it ought to be more patient and allow the distance to gradually open/close to the targeted distance, instead of braking/accelerating as hard as it does. [99% fixed now.]
- A lot of useful warnings seem to appear only on the screen. When I’m driving, I don’t have time to look at the screen and read them. It should say something.
2019-08-14
Software feature suggestion
- Not really an “issue”, but a feature suggestion. When parking in tight spaces the Model 3 notices nearby objects, chimes, and shows the distance to them on the screen. Better yet would be to automatically switch to the camera view showing the closest object (the car in the next spot, lamppost, whatever). Then the driver could easily see whether the car will fit on it’s current path. This would have saved me a scratch. Given that the cameras and sensors are already there, this seems easy to implement.
Check back later – I’ll add more things here if and as I discover them.